1. Introduction
The mini project I chose works on textual data, Confucius-Analects text. I decided to create a network graph treating people as nodes and treating speech-related relationships as edges. For example, Confucius, Tsze hsia, or Tsze lu would be nodes, while “asked”, “replied to”, “said to” would be edges. By converting philosophical text into a relational dataset represented by graph, this project allows for the “reading” of the Analects in a structural manner: who is positioned as an authority, who appears frequently, or how dialogue is distributed across the different characters in the text.
2. Sources
The primary dataset I used was the Confucius-Analexts.txt file, which is a plain-text transcription of The Analects. I used Voyant tool for preliminary data analysis in order to understand the text’s surface features and to identify the types of tokens and the structures for potential node/edge pairs. In particular, using Voyant I examined:
• Terms and frequency lists to see recurring markers of dialogue and attribution, such as “master”, “said”, or “tsze”.
• Contexts/ Reader views to confirm that the high-frequency terms, such as “The Master said…”, or “X asked…”, occurred in a consistent narrative templates that would be extractable as relations.
• Discern certain trends to see whether the aforementioned speech markers are distributed across the text rather than being confined to a small section of the text.
Then, I did some data cleanup / preprocessing using Python:
• normalization of character names: for example, combine “The Master” and “Master” as a single identity (Confucius) so the same person is not represented as redundant nodes.
def canon(name: str) -> str:
name = name.strip()
return "Confucius" if name in {"The Master", "Master", "Confucius"} else name• noise control: filtering out non-person placeholders, such as “someone”
STOP = {"Some one", "Someone", "Tsze", "He", "Ho"}
def clean_name(name: str) -> str:
name = name.strip()
return "" if name in STOP else name3. Processes
Based on the exploratory data analysis I did using Voyant, I further used Python to construct a proper dataset that is appropriate for creating a network graph (.csv file). Below are the rules I implemented in Python to extract meaningful node/edge relationship from the source text:
• Identify dialogue templates using regex pattern matching
ASK_RE = re.compile(r"^([A-Z][A-Za-z\s'-]+?)\s+asked\s+([A-Z][A-Za-z\s'-]+?)\b")
m = ASK_RE.match(line)
if m:
speaker, addressee = m.group(1), m.group(2)SAID_TO_RE = re.compile(r"^([A-Z][A-Za-z\s'-]+?)\s+said\s+to\s+([A-Z][A-Za-z\s'-]+?)\b")
m = SAID_TO_RE.match(line)
if m:
speaker, addressee = m.group(1), m.group(2)• Convert each events that have been detected into an edge record into the following format: source (speaker) → target (addressee) with an interaction label (for some semantic descriptor for the edge between the two nodes) and an aggregated weight (for frequency of interactions between the nodes).
edge_weight = defaultdict(int) # key: (source, target, interaction)
key = (source, target, "asked")
edge_weight[key] += 1edges = [
{"source": s, "target": t, "interaction": inter, "weight": w}
for (s, t, inter), w in edge_weight.items()
]• Then, I imported the output csv file from the python code to Cytoscape using the standard mapping: Source = source, Target = target, Interaction = source attribute, with weight as an edge attribute.
4. Presentation
In order to improve visual communication of the graph network I created, I made certain deliberate design choices:
• Directed edges (arrows pointing from source to destination), so that audience can know the asymmetric relationship between two figures which likely matters in a teacher-disciple text.
• Weighted edges to represent interactions that are repeated for stronger ties. The weights of each edge can be seen by clicking on the edge itself in the Cytoscape webtool.
• Reducing visual noise by collapsing redundant interactions involving same pairs of nodes into a single edge rather than multiple overlapping arrows that obstructs the visual simplicity.
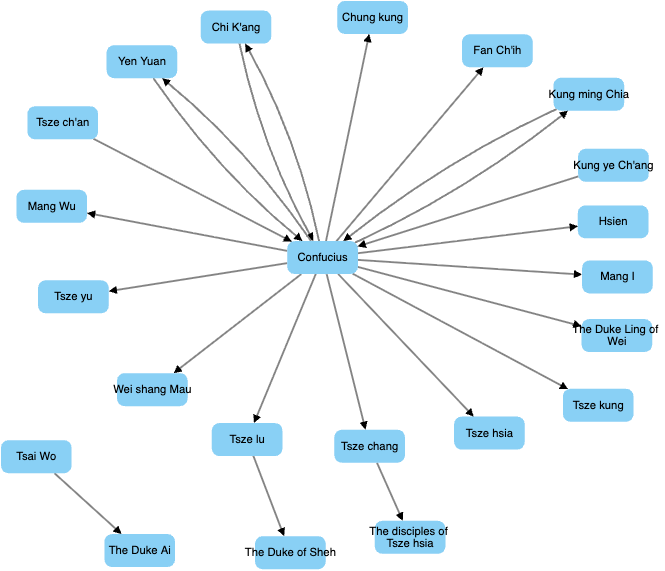
5. Significance
The significance of this project is that the graphical network data visualization provides insights that are hard to see through linear reading of the text. The graph network’s star-like shape is able to explicitly show that many actors ask questions or talk to one authoritative figure, Confucius. This is visualized not through just biographical prominence, but by using the textual structure of repeated patterns, such as “asked”, “said’, or “replied”. By designing this graph network to be a directed graph, the data visualization differentiates those who ask questions from those who answers the questions. Further, the graphical visualization makes it clear that there is a small disconnected component (Tsai Wo – Duke dialogue). This implies that there are moments where text’s social world is not strictly contained by the Confucius centered framework. Thus, this project is able to re-encode humanistic objects into computational representations, allowing to answer questions like “how the text organizes authority, interaction, and knowledge exchange”.